
어플리케이션 레이어 정리
Bandwidth, Throughput
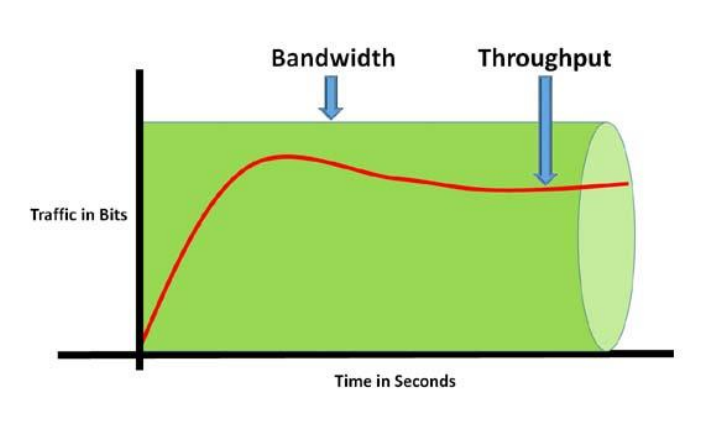
대역폭(Bandwidth):
대역폭은 네트워크 링크나 통신 채널이 전달할 수 있는 최대 데이터 전송 속도 또는 전송 가능한 데이터 양을 나타낸다. 대역폭은 보통 초당 비트수(bps)로 측정된다.
대역폭은 해당 링크의 물리적 특성에 따라 결정되며, 네트워크에서 정보를 전송하는 데 사용 가능한 최대 용량을 나타낸다.
예를 들어, 1 Gbps 대역폭의 이더넷 링크는 초당 1 기가비트의 데이터를 전송할 수 있다.
처리량(Throughput):
처리량은 실제로 전송된 데이터 양 또는 전송 속도로 정의된다. 즉, 대역폭과 다른 링크에서 발생하는 다양한 요인에 따라 실제로 전달된 데이터 양이다.
처리량은 네트워크의 현재 상태, 혼잡도, 패킷 손실 및 다른 네트워크 지연과 같은 요소에 영향을 받는다.
예를 들어, 1 Gbps 대역폭을 가진 링크가 혼잡하거나 패킷 손실이 발생할 경우, 처리량은 대역폭보다 낮을 수 있다
Throughput < Bandwidth
항상 Bandwidth보다 작다
Delay, Latency, RTT
Packet delay: 처리 + 대기열 + 전송 + 전파
• 일반적으로 단방향
Latency(지연): 양방향 딜레이
Round Trip Times (RTT): 양방향 딜레이
Application layer: overvie
- 애플리케이션 레이어 프로토콜의 개념과 구현 측면을 이해
- 전송 레이어 서비스 모델
클라이언트-서버 패러다임과 피어-투-피어 패러다임 - 인기 있는 애플리케이션 레이어 프로토콜과 인프라를 조사하여 프로토콜 이해. 이에는 HTTP, SMTP, IMAP, DNS, 비디오 스트리밍 시스템, CDN 등이 포함
- 네트워크 애플리케이션을 프로그래밍하는 방법을 습득하며 소켓 API를 사용
Creating a network app
프로그램을 작성할 때
- 엣지끼리 커뮤니케이션 가능해야한다.
- 네트워크 통신을 구현해야한다.
예: 웹 서버 소프트웨어는 브라우저 소프트웨어와 통신한다.
네트워크 코어 장치에 대한 소프트웨어를 작성할 필요 없음
- 네트워크 코어 장치는 사용자 응용 프로그램을 실행하지 않음
- 끝 시스템에서의 응용 프로그램은 빠른 앱 개발과 전파를 가능하게 함
Client-server paradigm
오늘날 90%가 클라이언트 서버 아키텍처
server
- 답신 response/reply
- 항상 켜져있어야한다. -> 요청을 받고 답신을 주기 위해서 (언제 클라이언트로부터 요청이 올지 모르기 때문에)
- 영구적인 IP주소 -> IP 주소를 알아야 서버에 요청을 보낼 수 있어서
- 데이터 센터에서 주로 사용되며 확장을 위한 목적으로 배치된다.
clients
- 서버에 요청을 보내고 답신을 받음
- 간헐적으로 접속된다 -> 서버는 항상 켜져있고 클라이언트는 요청을 보내고 싶을 대 보낸다
- IP주소가 동적으로 바뀐다.
- 클라이언트는 서로 간에 직접적으로 통신하지 않는다. 반드시 서버를 경유하여 전달한다.
Peer-peer architecture
- 항상 켜져 있는 서버 없음
- 임의의 끝 시스템이 직접 통신
- 피어(동등한 참여자)가 다른 피어에게 서비스를 요청하고 다른 피어에게 서비스를 제공
- 자가 확장성 - 새로운 피어가 새로운 서비스 용량과 서비스 요구 사항을 제공
- 피어는 간헐적으로 연결되며 IP 주소가 변경됨 복잡한 관리
예시: P2P 파일 공유
Processes communicating
프로세스: 호스트 내에서 실행되는 프로그램
- 같은 호스트 내에서 두 프로세스가 OS에서 정의한 프로세스 간 통신을 사용하여 통신
- 서로 다른 호스트에 있는 프로세스는 메시지를 교환하여 통신
- 네트워크를 통한 메세지 교환의 주체
*참고: P2P(Peer-to-Peer) 아키텍처를 사용하는 응용 프로그램도 클라이언트 프로세스와 서버 프로세스를 가질 수 있다.
Sockets
프로세스는 소켓으로 메시지를 보내거나 받는다. 따라서 소캣을 이용하여 통신을 한다.
프로세스들은 자신이 사용하는 소캣을 하나씩 가지고 있다.
▪ 소켓은 문과 유사하다
• 메시지를 보내는 프로세스는 메시지를 문 밖으로 밀어낸다.
• 메시지를 수신하는 프로세스의 소켓으로 전달하기 위해 문 반대편의 전송 인프라에 의존한다.
• 두 개의 소켓이 관련된다: 각각 한 쪽에 하나씩
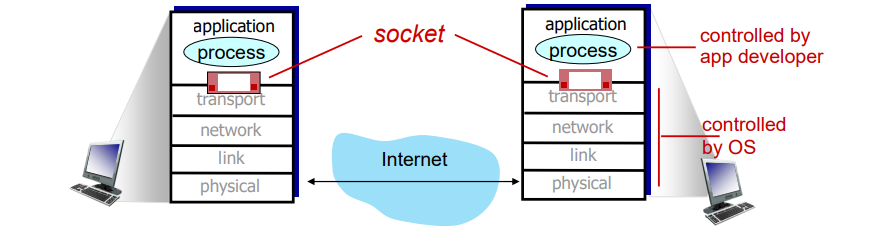
Addressing processes
메시지를 받으려면 프로세스가 식별자를 가져야 한다
호스트 기기는 고유한 32비트 IP 주소를 가지고 있다.
프로세스가 실행 중인 호스트의 IP 주소만으로 프로세스를 식별하는 데 충분한가?
-> 아니다, 동일한 호스트에서 여러 프로세스가 실행될 수 있다.
식별자는 호스트의 프로세스와 연결된 IP 주소와 포트 번호를 모두 포함한다.
호스트는 IP주소로 식별하고 프로세스는 포트번호로 식별한다.
하나의 호스트에 여러 개의 프로세스가 실행 중일 때 포트번호로 식별한다.
▪ 예시 포트 번호:
• HTTP 서버: 80
• 메일 서버: 25
▪ gaia.cs.umass.edu 웹 서버에 HTTP 메시지를 보내려면:
• IP 주소: 128.119.245.12
• 포트 번호: 80
An application-layer protocol defines:
응용 프로그램 계층 프로토콜은 다음을 정의합니다:
▪ 교환되는 메시지의 유형
예: 요청, 응답
▪ 메시지 구문:
메시지 내에서 어떤 필드가 있는지 및 필드가 어떻게 구분되는지
▪ 메시지 의미론:
필드 내의 정보의 의미
▪ 프로세스가 언제 및 어떻게 메시지를 보내고 응답하는지에 대한 규칙
▪ 오픈 프로토콜:
RFC(요청-평가-처분)에서 정의되며 모든 사람이 프로토콜 정의에 액세스할 수 있음
상호 운용성을 허용
예: HTTP, SMTP
▪ 프로프리터리 프로토콜:
예: Skype, Zoom
응용프로그램은 다양한 전송 서비스를 필요로한다.
데이터 무결성:
일부 응용 프로그램 (예: 파일 전송, 웹 트랜잭션)은 100% 신뢰성있는 데이터 전송을 요구한다.
다른 응용 프로그램 (예: 오디오 스트리밍)은 일부 데이터 손실을 허용할 수 있다.
타이밍:
일부 응용 프로그램 (예: 인터넷 전화, 대화형 게임)은 "효과적"이 되기 위해 낮은 지연 시간을 필요로 한다.
대역폭:
일부 응용 프로그램 (예: 멀티미디어 스트리밍)은 "효과적"이 되기 위해 최소한의 대역폭을 필요로 한다..
다른 응용 프로그램( "탄성 앱")은 사용 가능한 대역폭을 활용한다.
보안:
암호화, 데이터 무결성 등을 통한 보안이 필요한 경우가 있다.
Internet transport protocols services
TCP 서비스:
- 송신 및 수신 프로세스 간의 신뢰성 있는 전송
- 흐름 제어: 송신자가 수신자를 압도하지 않도록 함
- 혼잡 제어: 네트워크가 과부하 상태일 때 송신자를 조절
- 연결 지향: 클라이언트 및 서버 프로세스 간에 설정이 필요
- 제공하지 않는 것: 타이밍, 최소 대역폭 보장, 보안
UDP 서비스:
- 송신 및 수신 프로세스 간의 신뢰성 없는 데이터 전송
- 제공하지 않는 것: 신뢰성, 흐름 제어, 혼잡 제어, 타이밍, 대역폭 보장, 보안 또는 연결 설정

UDP or TCP가 된 이유는 오늘날에는 TCP의 속도가 UDP의 속도를 거의 따라잡았기 때문에 둘 중 하나를 사용하는 것이다.
Web and HTTP
웹 페이지는 서로 다른 웹 서버에 저장될 수 있는 여러 객체로 구성된다.
▪ 객체는 HTML 파일, JPEG 이미지, Java 애플릿, 오디오 파일 등이 될 수 있다.
▪ 웹 페이지는 여러 참조된 객체를 포함하는 기본 HTML 파일로 구성되며 각 객체는 URL로 주소 지정된다.

HTTP overview
HTTP: 하이퍼텍스트 전송 프로토콜
▪ 웹의 응용 프로그램 계층 프로토콜
▪ 클라이언트/서버 모델:
• 클라이언트: HTTP 프로토콜을 사용하여 웹 객체를 요청, 수신하고 "표시"하는 브라우저
• 서버: HTTP 프로토콜을 사용하여 요청에 대한 응답으로 객체를 웹 서버에서 보냄

HTTP는 TCP를 사용한다. ( 정확하게 전송하는 것이 중요하기 때문에 TCP를 사용한다)
▪ 클라이언트는 서버의 포트 80으로 TCP 연결을 초기화한다 (소켓을 생성).
▪ 서버는 클라이언트로부터의 TCP 연결을 수락한다. -> 연결은 메세지를 보내기전에 보내도 되는지 확인을 받는 것을 말한다. 클라이언트가 먼저 웹서버한테 TCP 커넥션 생성을 요청한다.
▪ HTTP 메시지(응용 프로그램 계층 프로토콜 메시지)가 브라우저 (HTTP 클라이언트)와 웹 서버 (HTTP 서버) 간에 교환된다.
▪ TCP 연결이 종료된다.
HTTP는 "상태를 유지하지 않는" 프로토콜이다. (프로토콜은 컴퓨터 네트워크와 통신 시스템에서 데이터를 교환하는 데 사용되는 규칙과 규정의 집합)
▪ 서버는 이전 클라이언트 요청에 대한 정보를 유지하지 않는다.
HTTP connections: two types
비지속적인 HTTP
1.TCP 연결이 열림
2.최대 한 개의 객체가 TCP 연결을 통해 전송됨
3.TCP 연결이 종료됨
여러 객체를 다운로드하려면 여러 연결이 필요함
지속적인 HTTP
▪ 서버로 TCP 연결이 열림
▪ 클라이언트와 해당 서버 간에 단일 TCP 연결을 통해 여러 개체가 전송될 수 있음
▪ TCP 연결이 닫힘
하나의 연결을 계속 재활용하여 사용한다.
Non-persistent HTTP: example
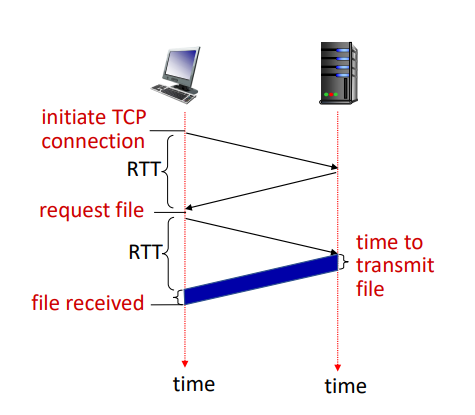
항상 커넥션을 새로 수립한다. 또한 HTTP 반응 시간은 = 2RTT + 파일 전송시간이다
RTT(라운드 트립 타임): 클라이언트에서 서버로 작은 패킷이 이동하고 다시 돌아오는 데 걸리는 시간
HTTP 응답 시간(각 객체 당):
▪ TCP 연결을 시작하기 위한 한 번의 RTT
▪ HTTP 요청 및 HTTP 응답의 처음 몇 바이트를 반환하는 데 한 번의 RTT
▪ 객체/파일 전송 시간
Persistent HTTP (HTTP 1.1)
비지속적인(non-persistent) HTTP의 이슈:
▪ 객체 당 2개의 RTT가 필요
▪ 각 TCP 연결마다 운영 체제 오버헤드
▪ 브라우저는 종종 병렬로 참조된 객체를 가져오기 위해 여러 개의 TCP 연결을 동시에 연다
지속적인(persistent) HTTP (HTTP 1.1):
▪ 서버는 응답을 보낸 후 연결을 열어둠
▪ 동일한 클라이언트/서버 간의 이후 HTTP 메시지는 열린 연결을 통해 전송
▪ 클라이언트는 참조된 객체를 만나자마자 요청을 보냄
▪ 참조된 객체에 대한 모든 요청에 대해 하나의 RTT만 소요(응답 시간을 절반으로 줄임)
지속적인 HTTP는 커넥션을 한번만 열어두면 다시 연결하지 않아도 되기 때문에 RTT가 절반으로 준다.
Other HTTP request messages
POST 방식:
▪ 웹 페이지에는 종종 양식 입력이 포함됨
▪ 사용자 입력은 HTTP POST 요청 메시지의 엔터티 본문에 있는 클라이언트에서 서버로 전송됨
GET 방식 (데이터를 서버로 보내는 경우):
▪ 사용자 데이터를 HTTP GET 요청 메시지의 URL 필드에 포함(물음표 뒤에 따라옴):
http://www.somesite.com/animalsearch?monkeys&banana
HEAD 방식:
▪ 지정된 URL로 HTTP GET 방식으로 요청되었을 때 반환될 헤더만 요청
PUT 방식:
▪ 새 파일(객체)을 서버로 업로드
▪ POST HTTP 요청 메시지의 엔터티 본문의 내용으로 지정된 URL에 있는 파일을 완전히 대체
HTTP response status codes
HTTP 응답 상태 코드:
200 OK
• 요청이 성공하고 요청된 객체가 이 메시지의 뒷부분에 있음
301 Moved Permanently
• 요청된 객체가 이동했으며, 새로운 위치가 이 메시지의 뒷부분(위치(Location) 필드에 지정됨)에 명시됨
400 Bad Request
• 서버가 요청 메시지를 이해하지 못함
404 Not Found
• 요청된 문서가 이 서버에서 찾을 수 없음
505 HTTP 버전이 지원되지 않음
Maintaining user/server state: cookies
기억해야 할 것: HTTP GET/응답 상호 작용은 상태를 유지하지 않음
▪ HTTP 메시지의 다단계 교환을 통해 웹 "트랜잭션"을 완료하는 개념이 없습니다.
• 클라이언트/서버가 다단계 교환의 "상태"를 추적할 필요 없음
• 모든 HTTP 요청은 서로 독립적임
• 부분적으로 완료되었지만 결코 완전히 완료되지 않은 트랜잭션에서 "복구"할 필요 없음
사용자/서버 상태 유지: 쿠키
웹 사이트와 클라이언트 브라우저는 트랜잭션 간에 일부 상태를 유지하기 위해 쿠키를 사용한다.
네 가지 구성 요소:
1. HTTP 응답 메시지의 쿠키 헤더 라인: 서버가 클라이언트에게 쿠키 정보를 제공하는 데 사용된다
2. 다음 HTTP 요청 메시지의 쿠키 헤더 라인: 클라이언트가 서버에게 쿠키 정보를 다시 보내는 데 사용된다.
3. 사용자 호스트에서 관리되는 쿠키 파일: 이 파일은 사용자의 브라우저에서 관리되며 쿠키 정보를 저장한다.
4. 웹 사이트의 백엔드 데이터베이스: 이 데이터베이스는 클라이언트의 쿠키 정보와 관련된 정보를 유지하고 저장한다.
예시:
▪ Susan은 노트북에서 브라우저를 사용하고 특정 전자 상거래 사이트를 처음 방문
▪ 초기 HTTP 요청이 사이트에 도착할 때, 사이트는 다음을 생성:
• 고유 ID(쿠키라고도 함)
• ID에 대한 백엔드 데이터베이스 항목
• Susan이 이 사이트로부터의 후속 HTTP 요청에 쿠키 ID 값을 포함하게 됩니다. 이로써 사이트는 Susan을 "식별"할 수 있게 됩니다.

상태를 유지하는 도전 과제:
▪ 프로토콜의 끝점에서: 여러 트랜잭션을 통해 발신자 및 수신자에서 상태를 유지
▪ 메시지에서: HTTP 메시지의 쿠키를 사용하여 상태를 전달
Web caches
목표: 원본 서버를 참여시키지 않고 클라이언트 요청을 처리하는 것

사용자는 브라우저를 로컬 웹 캐시를 가리키도록 설정한다.
▪ 브라우저는 모든 HTTP 요청을 캐시로 보낸다.
• 캐시에 객체가 있는 경우: 캐시는 객체를 클라이언트에 반환한다.
• 그렇지 않은 경우 캐시는 원본 서버에서 객체를 요청하고, 받은 객체를 캐시에 저장한 다음 클라이언트에 객체를 반환한다.
orgin server의 내용(자주 방문하는 사이트 등)을 web cache에 엑세스한다
client는 접속할 때 server가 아닌 web cache에 먼저 접속한다. cache에 내용이 있으면 cache에서 내용을 받는다.
->latency(packet delay)가 1/2로 줄어든다.
Web caches (aka proxy servers)
proxy server: 프록시 서버는 클라이언트와 서버의 역할을 동시에 수행한다.
즉 웹 캐시는 원래 요청한 클라이언트에 대한 서버 역할을 하며, 원본 서버에 대한 클라이언트 역할을 한다.
서버는 응답 헤더에서 캐싱을 허용하는 객체에 대한 캐시에 정보를 전달한다.
웹 캐시는 프록시 서버로 캐시 miss가 발생한 경우 origin server에 내용을 요청한다.
서버는 응답 헤더에서 캐싱을 허용하는 객체에 대한 캐시에 정보를 전달한다.
웹 캐싱의 이유:
▪ 클라이언트 요청에 대한 응답 시간을 줄임
• 캐시는 클라이언트에 가깝기 때문
▪ 기관의 액세스 링크의 트래픽을 줄임
▪ 인터넷은 캐시로 가득차 있음
• "부족한" 콘텐츠 제공자가 콘텐츠를 효과적으로 제공할 수 있도록 함
Caching example

bandwidth가 작은 곳에서 bottleneck (병목현상) 발생한다 -> 인터넷 느려짐 버퍼링 발생
내부망은 1Gbps로 큰데 외부는 1.54Mbsp로 작아서 큐잉 딜레이, 패킷 로스가 발생한다.
Option 1: buy a faster access link
해결책: 엑세스 링크를 업그레이드 한다.
-> 하지만 빠른 엑세스 링크는 값이 비싸다.
Option 2: install a web cache
웹 캐시를 설치한다.
웹 캐시를 설치하면 엑세스 링크로 몰리는 트래픽 양이 감소한다.
DNS: Domain Name System
호스트는 ip 주소로 구별한다.
도메인 네임을 ip 주소로 변환해주는 것이 DNS( 도메인 네임 서버)이다
ip주소는 외우기가 어렵기 때문에 도메인 네임을 사용한다.
도메인 이름 시스템(Domain Name System, DNS):
▪ 계층화된 많은 이름 서버의 계층 구조에서 구현된 분산 데이터베이스
▪ 응용 계층 프로토콜: 호스트 및 DNS 서버는 이름 해석(주소/이름 변환)을 위해 통신
• 참고: 핵심 인터넷 기능으로, 응용 계층 프로토콜로 구현
• 네트워크 엣지단에서의 복잡성을 갖음
DNS 서비스:
▪ 호스트 이름에서 IP 주소로의 변환
▪ 호스트 별칭
• 정식 별칭, 별칭 이름
▪ 메일 서버 별칭
▪ 부하 분산 -> 복제된 웹 서버: 여러 IP 주소가 하나의 이름에 대응
즉 하나의 도메인 네임에 여러개의 ip주소를 매핑한다.
Q: 왜 DNS를 중앙집중화하지 않나요?
▪ 단일 장애 지점 (SPoF)
▪ 트래픽 양
▪ 원격 중앙 집중식 데이터베이스
▪ 유지 보수
A: 확장이 어려워서!
▪ Comcast DNS 서버만: 하루에 600억 개의 DNS 쿼리
▪ Akamai DNS 서버만: 하루에 2.2조 개의 DNS 쿼리
DNS: a distributed, hierarchical database
DNS는 분산적이고 계층적이다.

클라이언트가 http://www.amazon.com의 IP 주소를 원할 때, 처음에는 다음과 같은 과정을 거친다:
▪ 클라이언트가 루트 서버에 .com DNS 서버를 찾기 위한 쿼리를 보낸다.
▪ 클라이언트가 .com DNS 서버에 amazon.com DNS 서버를 찾기 위한 쿼리를 보낸다.
▪ 클라이언트가 amazon.com DNS 서버에 http://www.amazon.com의 IP 주소를 얻기 위한 쿼리를 보낸다.
DNS: root name servers
루트 네임 서버는 DNS에 의해 이름 해석이 불가능한 경우, 이름 서버의 공식적인 연락처 또는 마지막 수단으로 사용된다.
▪ 극도로 중요한 인터넷 기능
• DNS 없이 인터넷은 작동하지 않는다!
• DNSSEC - 보안(인증, 메시지 무결성)을 제공
▪ ICANN(인터넷 주소 및 이름 할당 단체)은 루트 DNS 도메인을 관리한다.
Top-Level Domain, and authoritative servers
최상위 도메인(Top-Level Domain, TLD) 서버:
▪ .com, .org, .net, .edu, .aero, .jobs, .museums 및 모든 최상위 국가 도메인 (예: .cn, .uk, .fr, .ca, .jp)에 대한 책임을 지는 서버
▪ Network Solutions: .com, .net TLD의 권위 있는 레지스트리
▪ Educause: .edu TLD
권위 있는 DNS 서버:
▪ 조직 자체의 DNS 서버(들), 조직의 명명된 호스트에 대한 권위 있는 호스트 이름에서 IP 매핑을 제공
▪ 조직 또는 서비스 제공업체에 의해 유지될 수 있음
Local DNS name servers
지역 도메인 서버는 캐시 역할을 한다.
호스트가 DNS 쿼리를 수행할 때, 해당 쿼리는 로컬 DNS 서버로 전송된다.
• 로컬 DNS 서버는 최근 이름-주소 변환 쌍의 로컬 캐시에서 답변을 반환한다(가능한 경우 오래된 정보일 수 있음).
• DNS 해결을 위한 DNS 계층에 쿼리를 전달한다.
• 각 ISP(인터넷 서비스 제공업체)는 로컬 DNS 이름 서버를 가지고 있으며,
내 것을 찾으려면:
• macOS: % scutil --dns
• Windows: >ipconfig /all
▪ 로컬 DNS 서버는 엄격히 말하면 계층에 속하지 않는다.
DNS name resolution: iterated query
Ip주소를 알아내는 방법
example: engineering.nyu.edu에 있는 호스트가 gaia.cs.umass.edu의 IP 주소를 원하는 경우

먼저 root DNS server에 1차적으로 물어보고 그 다음 TLD DNS server에 2차적으로 물어본다.
그 후 authoritative DNS server에 물어본 다음 local dns서버에 새로 등록해준다-> cache miss가 발생하면 cache에 내용을 저장해줘야한다.
Socket programming
목표: 소켓을 사용하여 통신하는 클라이언트/서버 응용 프로그램을 구축하는 방법을 배우기
소켓: 응용 프로세스와 끝 간 전송 프로토콜 간의 문이다.
*끝 간 전송 (end-to-end transport)은 컴퓨터 네트워크에서 데이터를 송수신하는 두 단말 간의 통신을 의미합니다. 이것은 데이터를 보내는 끝(송신자)에서 데이터를 받는 끝(수신자)까지의 전송을 다루는 것을 의미

두 가지 전송 서비스에 대한 두 가지 소켓 유형:
▪ UDP: 신뢰성 없는 데이터그램
▪ TCP: 신뢰성이 있으며 바이트 스트림 지향
응용 프로그램 예:
1.클라이언트는 키보드에서 문자(데이터) 한 줄을 읽고 데이터를 서버로 보낸다.
2.서버는 데이터를 수신하고 문자를 대문자로 변환한다.
3.서버는 수정된 데이터를 클라이언트로 보낸다.
4.클라이언트는 수정된 데이터를 받아 화면에 표시한다.
Socket programming with UDP
UDP: 클라이언트와 서버 간에 "연결"이 없다(TCP는 연결한다):
▪ 데이터를 전송하기 전에 handshaking이 없음( 커넥션 수립과정이 없음)
▪ 송신자는 각 패킷에 IP 대상 주소와 포트 번호를 명시적으로 첨부한다.
▪ 수신자는 수신한 패킷에서 송신자의 IP 주소와 포트 번호를 추출한다.
UDP: 전송된 데이터는 손실될 수 있거나 순서가 뒤섞일 수 있다.
응용프로그램 관점에서:
▪ UDP는 클라이언트와 서버 프로세스 간의 바이트 그룹("데이터그램")의 신뢰성 없는 전송을 제공합니다.
Client/server socket interaction: UDP

AF_INET : IPv4를 사용한다는 뜻
SOCK_DGRAM: UDP를 사용하겠다는 것
(TCP는 SOCK_STREAM)
socket("") : 소캣 생성 함수

sendto: 패키 전달
recvfrom: 소캣에 데이터를 읽어옴
close()함수로 꼭 닫아줄 것

bind: 소캣 바인딩 ( 소캣에 포트번호를 입혀주는 것 )
'{Lecture} > Computer Network' 카테고리의 다른 글
| 컴퓨터 네트워크 과제 echo software router 구현 (0) | 2024.06.05 |
|---|---|
| 컴퓨터 네트워크 과제 rdt2.2 over UDP 구현 과제 (0) | 2024.06.05 |
| 컴퓨터 네트워크 과제 UDP Echo server 구현 (0) | 2024.06.05 |
| [NetWork] 네트워크 정리 (3) (0) | 2023.10.28 |
| [NetWork] 네트워크 정리 (1) (0) | 2023.10.27 |



